

09/02/2021
Prévoir le monde de demain, Paul Dahan (dir.)

« Regarder l’avenir, c’est déjà le changer », disait Gaston Berger. Mais alors, comment faut-il l’observer quand on ambitionne de le transformer ? Quels types de regards lui adresser ? Selon quelles démarches et avec quels degrés de réussite ? Voici les interrogations principales auxquelles essaie de répondre ce livre collectif, riche et dense, rédigé par une quinzaine d’universitaires, chercheurs et experts, tous réputés dans leur domaine.
Les chapitres, contrastés mais bien complémentaires, abordent à la fois les questions de définition et de méthode, d’histoire ancienne et de gouvernance contemporaine, de réussite et d’échec des pratiques prévisionnistes. Les registres et secteurs étudiés sont eux aussi divers : simulations économiques, prospective de défense, relations internationales, développement durable, apports des services de renseignement, etc. Deux textes intéressants décrivent les conditions nécessaires au bon fonctionnement des équipes de prévision au sein du monde administratif, en France comme à Bruxelles. Deux autres, également à retenir, s’interrogent sur « l’avenir de la prévision », entre intelligence artificielle, machine learning et société numérique. Signalons enfin plusieurs contributions, centrées sur la « pertinence de la prévision » et sur les qualités et attitudes qu’elle réclame : patience et sobriété, culture générale et empathie, rigueur, neutralité axiologique. Autant dire que ces conditions ne sont pas toujours réunies et que les prévisionnistes rencontrent souvent de nombreuses limites !
Au-delà de ces analyses de sujets précis, le livre dégage quelques grandes leçons sur les heurs et malheurs de l’anticipation au service de l’action politique. Il rappelle la quête sans fin, à travers l’histoire, des signes avant-coureurs du futur et du sens à leur donner. Il montre aussi la recherche croissante d’un avenir calculable dans des sociétés de plus en plus complexes où subsiste toujours une part d’indécidable. Prévoir est d’autant plus difficile que le manque de rigueur préside à de nombreuses réflexions prospectives et que la place de l’anticipation est mal assurée dans les organisations. Et pour que la prévision débouche sur de l’action il faut, du côté des décideurs, que le seuil d’acceptabilité de l’imprévu soit élevé. Les auteurs rappellent que cette condition n’est pas souvent remplie car, comme le disait Michel Serres, « ceux qui gouvernent commandent un monde qui se transforme pour des raisons qu’ils ignorent ».
Bruno Hérault, Centre d’études et de prospective
Lien : CNRS Éditions
15:27 Publié dans 3. Prévision, 4. Politiques publiques, 5. Fait porteur d'avenir | Lien permanent | Tags : action publique, machine learning, gouvernement, anticipation, prévision |  Imprimer | |
Imprimer | |  |
|  Facebook
Facebook
11/11/2020
Les big data pour analyser les différences de productivité d'une exploitation forestière mécanisée
Dans des situations d'exploitation forestière similaires, deux opérateurs d'abatteuses peuvent travailler de façons différentes, conduisant à des variations de productivité. Dans un article publié dans l'European Journal of Forest Research, une équipe finlandaise a cherché à en identifier les sources : environnementales, humaines ou paramétriques. Elle a caractérisé le milieu forestier dans lequel évoluaient les abatteuses, en traitant par machine learning les données d'inventaire (peuplements et sols), récemment harmonisées et accessibles librement. Les croisant avec les données massives recueillies par les machines, les auteurs ont ainsi dégagé des différences de productivité (consommation de carburant et volume récolté), à environnement égal. Si certains des paramètres sont dépendants de l'action de l'opérateur, comme la vitesse, d'autres sont liés aux paramétrages du système de pilotage. Ces travaux permettent d'identifier des enjeux à court terme de formation des opérateurs, mais sont aussi essentiels pour la mise au point d'abatteuses autonomes.
Source : European Journal of Forest Research
16:43 Publié dans 5. Fait porteur d'avenir, Forêts Bois | Lien permanent | Tags : machine learning, forêt-bois, productivité, big data | Imprimer | | | Facebook
15/09/2020
L'agriculture et l'aquaculture, premières causes de déforestation des mangroves dans le monde
Dans un article de juin 2020 publié dans Global Change Biology, le traitement d'images satellitaires par des méthodes d'apprentissage automatique (machine learning) montre que les activités humaines sont responsables, au niveau mondial, de 62 % de la déforestation des mangroves entre 2000 et 2016. 47 % de ces pertes sont dues à une conversion pour des productions agricoles ou aquacoles.
La Birmanie, l'Indonésie, la Malaisie, les Philippines, la Thaïlande et le Vietnam concourent à eux seuls à 80 % de la déforestation anthropique des mangroves. La conversion des surfaces pour l'agriculture et l'aquaculture y est la principale cause, bien que sa part de responsabilité diminue fortement au cours du temps. Les politiques nationales encourageant l'intensification de l'aquaculture expliqueraient en partie ce phénomène. Par ailleurs, dans les autres pays, l'ensemble des activités humaines sont, en moyenne, à l'origine de 33 % des pertes de mangroves.
Perte annuelle de surface (km²) de mangroves entre 2000 et 2016, selon la cause
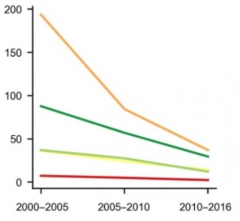
Source : Global Change Biology
Lecture : orange : conversion de surfaces ; vert foncé : érosion ; vert clair : événements climatiques extrêmes ; rouge : urbanisation et autres types d'occupation des terres.
Source : Global Change Biology
15:46 Publié dans Forêts Bois, Pêche et aquaculture | Lien permanent | Tags : machine learning, déforestation, mangroves | Imprimer | | | Facebook
15/01/2020
Les effets positifs de l'agriculture de conservation sur les rendements dans la Corn Belt
Un article récent, publié dans la revue Environmental Research Letters par des chercheurs de l'université de Stanford, s'intéresse aux effets des pratiques d'agriculture de conservation sur les rendements du maïs et du soja dans la Corn Belt des États-Unis. Selon les auteurs, la littérature sur le sujet, bien que riche, ne permet pas toujours de conclure en raison de la variété des conditions de culture, des pratiques, des profils pédoclimatiques, etc. Ils proposent ici une approche originale, en utilisant des bases de données issues d'observations satellitaires et en analysant les données avec des algorithmes de machine learning. Les résultats montrent que les pratiques d'agriculture de conservation permettent d'augmenter le rendement de 3,3 % en moyenne pour le maïs et de 0,74 % pour le soja. Cet effet positif est en revanche plus limité pour les parcelles venant de passer récemment en agriculture de conservation, probablement en raison du temps nécessaire pour que la qualité des sols évolue et que les agriculteurs utilisent de façon optimisée ces pratiques (cf. figure).
Résumé des impacts moyens de l'agriculture de conservation sur les rendements en fonction de la durée de mise en œuvre
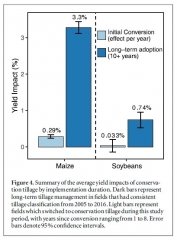
Source : Environmental Research Letters
Source : Environmental Research Letters
14:47 Publié dans Agronomie, Exploitations agricoles | Lien permanent | Tags : corn belt, agriculture de conservation, machine learning, rendements, maïs, soja | Imprimer | | | Facebook
15/02/2019
Que peut le deep learning pour l’agriculture ?
La chaire AgroTIC consacre une étude au deep learning et à ses applications en agriculture. Il est présenté comme une variété de machine learning, cette branche de l’intelligence artificielle qui vise à « donner la capacité d’apprendre à la machine, par elle-même, quelle que soit la situation » et sans avoir à coder « ni même à connaître » toutes les règles. En cela, le deep learning repose sur une analogie avec le fonctionnement du cerveau. Empilant plusieurs couches de neurones formels, l'apprentissage profond nécessite d’importantes capacités de calcul.
Le machine learning
Source : Chaire AgroTIC
Dès 2010, le deep learning était utilisé en élevage pour contrôler les paramètres de croissance du poulet de chair. À partir de 2012, il connaît un rapide développement dans le domaine de l’analyse d’images, certains parlant de « révolution ». Aujourd'hui, de nombreuses applications couplent ces systèmes de traitement de l'information avec des machines agricoles, des drones ou des robots : reconnaissance des plantes ou détection des maladies pour la pulvérisation et le désherbage, classification de l'occupation des sols et estimation de rendements, etc.
L'étude livre d'intéressants verbatim d'entrepreneurs du deep learning. Elle souligne aussi les enjeux de son déploiement. Pour un apprentissage efficace, de grands jeux de données annotées sont nécessaires en amont des mises en situation (« entraînement » du modèle par l'algorithme, tests de fiabilité). Il est donc important de régler les questions de mutualisation et de propriété des données, et la réglementation peut ici être un frein. De plus, le hardware n'est pas facile à embarquer sur les machines agricoles. Enfin, l’effet « boîte noire » inhérent au fonctionnement du système pose aussi des questions d'autonomie et de confiance. Il est quasiment impossible, même pour leurs concepteurs, de retracer ce qui se passe « à l'intérieur » de ces machines apprenantes. Il peut donc être difficile d'améliorer leurs performances, de dégager les responsabilités en cas de défaillance et, a fortiori, d'assurer les risques liés à leur utilisation.
Florent Bidaud, Centre d'études et de prospective
Source : Chaire AgroTIC
13:56 Publié dans 5. Fait porteur d'avenir | Lien permanent | Tags : deep learning, machine learning, chaire agrotic | Imprimer | | | Facebook
14/12/2018
Machine Learning au service de l'épidémiologie : ciblage des restaurants à inspecter par les services sanitaires aux États-Unis
En novembre 2018 ont été diffusés les résultats de travaux menés, aux États-Unis, par Google, l'université Harvard et les départements de santé et d'innovation de Las Vegas et Chicago, visant à améliorer le ciblage des restaurants à contrôler par les services sanitaires.
L'équipe de recherche a tout d'abord mis en place un algorithme de détection des requêtes, lancées sur le navigateur web Google, concernant des problèmes de santé consécutifs à la consommation d'aliments dans des conditions sanitaires médiocres. L'algorithme permet de distinguer les personnes effectivement malades de celles faisant des recherches dans un autre cadre : par exemple, les médecins et les étudiants peuvent se renseigner sur certains symptômes sans être eux-mêmes atteints. Il vérifie également si les personnes, dont les requêtes ont été identifiées comme pertinentes, sont bien allées au restaurant les jours précédents, ce grâce au service de localisation de Google (sous réserve qu'il n'ait pas été désactivé). Les restaurants sont ensuite classés comme « à risque » lorsqu'ils sont à l'origine d'une proportion importante de requêtes. L'application ainsi construite (FINDER) a été déployée dans les services sanitaires de Chicago (de novembre 2016 à mars 2017) et de Las Vegas (de mai à août 2016).
52,3 % des restaurants, identifiés par FINDER et contrôlés par les services sanitaires, se sont avérés non conformes lors des inspections, contre 24,7 % en temps normal. Comparativement, 39,4 % des restaurants contrôlés à Chicago suite au dépôt d'une plainte se sont révélés non conformes (résultats de Las Vegas non disponibles), soit une efficacité de détection moindre par rapport à FINDER. Ceci s'explique notamment par le fait qu'une personne peut avoir des difficultés à identifier quel restaurant l'a rendue malade, parmi ceux visités.
Ainsi, pour les auteurs, FINDER est un outil prometteur d'aide à la mise en œuvre de politiques sanitaires dans le secteur de la restauration, en améliorant le ciblage des inspections. Cette application présente l'avantage de ne pas nécessiter d'action de la part des consommateurs (par ex. porter plainte). Cependant, elle suppose un accès à leurs données personnelles de localisation et de recherches Google. Concernant le coût de mise en place de l'outil, les services testeurs rapportent qu'un certain effort a été nécessaire au début, mais qu'une fois pris en main, sa maintenance nécessite peu de ressources et de temps, tout en leur fournissant des indications précieuses pour mener leurs enquêtes terrain.
Nombre moyen d'infractions à la réglementation par catégorie (« critique » ou « majeure ») rencontrées dans les restaurants identifiés par FINDER ou non (Baseline)
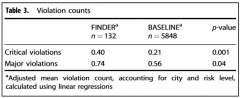
Source : npj Digital Medicine
Aurore Payen, Centre d'études et prospective
Source : npj Digital Medicine
09:46 Publié dans 4. Politiques publiques, 5. Fait porteur d'avenir, Santé et risques sanitaires | Lien permanent | Tags : machine learning, inspections sanitaires, restaurants, google | Imprimer | | | Facebook